Halusinasi AI: Analisis Kadar Ralat 4 Model Utama (Kajian 2026)
Pernahkah anda menggunakan kecerdasan buatan (AI) untuk merumus kertas kajian atau mencari fakta penting, hanya untuk menyedari kemudiannya bahawa maklumat yang diberikan rupa-rupanya tidak wujud? Fenomena ini dikenali sebagai halusinasi AI (AI hallucination).
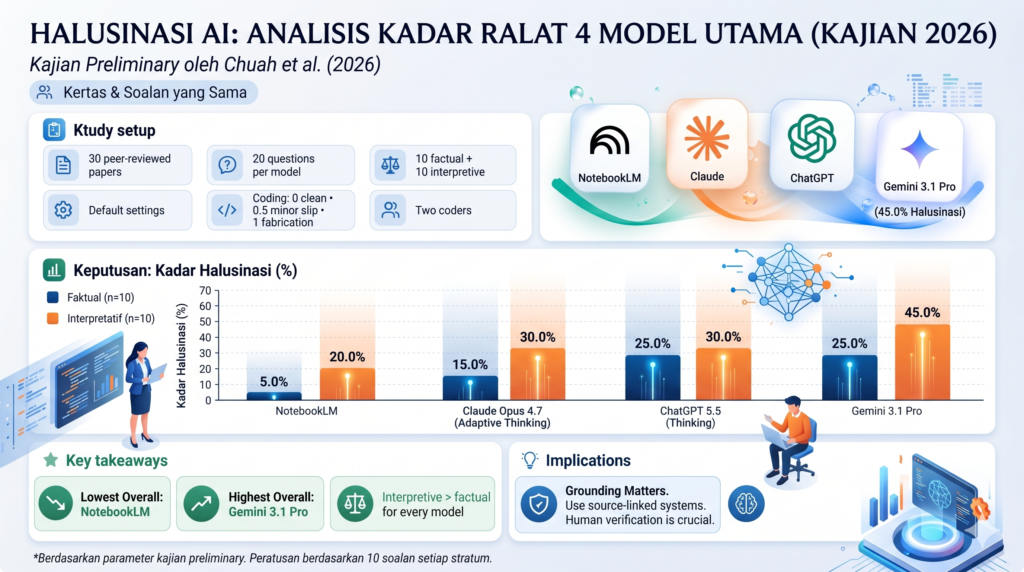
Dalam satu kajian awal terbaharu oleh Encik Chuah. (2026), empat sistem AI terkemuka telah diuji dalam keadaan persekitaran yang sama berasaskan artikel akademik (paper-based conditions). Setiap model diberikan 30 kertas jurnal bertaraf penilai tara (peer-reviewed) dan diminta menjawab 20 soalan yang sama merangkumi aspek faktual dan interpretatif.
Hasilnya? Ada berita baik, dan ada juga amaran penting yang perlu kita beri perhatian.
Keputusan Kajian: Model Mana Paling Kurang Mengalami Halusinasi AI?
Kajian ini membahagikan soalan kepada dua kategori utama: soalan faktual (contohnya: “Berapakah saiz sampel yang digunakan oleh pengkaji X?”) dan soalan interpretatif (contohnya: “Sejauh manakah kajian-kajian ini mencapai persetujuan tentang topik X?”).
Berikut adalah pecahan kadar halusinasi bagi setiap model yang diuji:
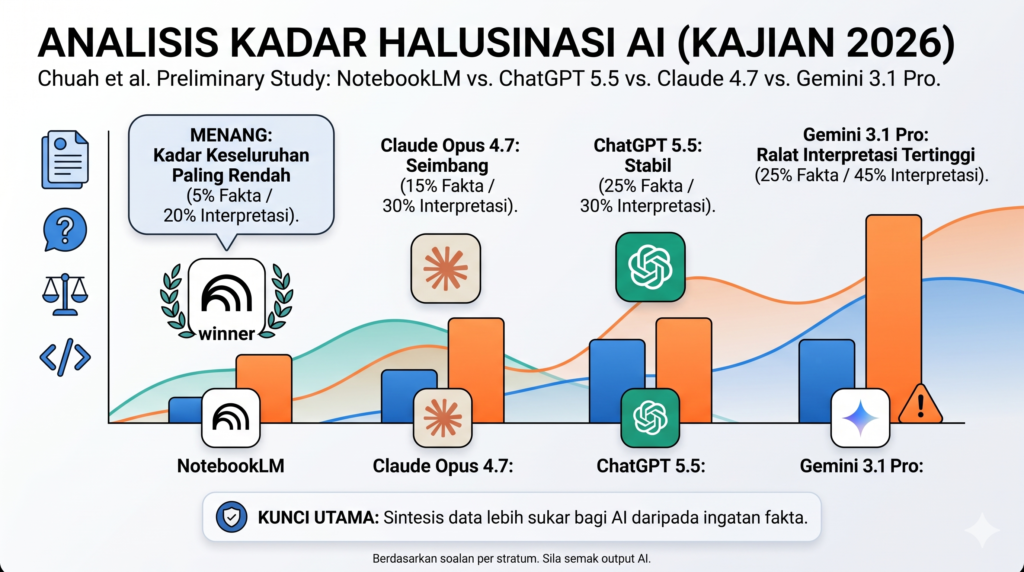
1.NotebookLM: Kadar Halusinasi AI Paling Rendah
- Faktual: 5.0%
- Interpretatif: 20.0%
- Rumusan: Mencatatkan kadar halusinasi keseluruhan paling rendah. Keupayaan penyandaran sumber (source grounding) yang kuat dalam NotebookLM terbukti banyak membantu mengekalkan ketepatan data.
2. Claude Opus 4.7 (Adaptive Thinking)
- Faktual: 15.0%
- Interpretatif: 30.0%
- Rumusan: Menunjukkan prestasi yang agak seimbang, namun jurang antara tugasan faktual dan interpretasi tetap kelihatan ketara.
3. ChatGPT 5.5 (Thinking)
- Faktual: 25.0%
- Interpretatif: 30.0%
- Rumusan: Model pemikiran (thinking model) ini menunjukkan kestabilan pada tahap 30% untuk tugasan kompleks, tetapi kadar kesilapan faktualnya sedikit tinggi berbanding dua model di atas.
4. Gemini 3.1 Pro: Risiko Ralat Fakta AI Tertinggi
- Faktual: 25.0%
- Interpretatif: 45.0%
- Rumusan: Mencatatkan kadar halusinasi keseluruhan paling tinggi, terutamanya apabila diminta melakukan sintesis dan interpretasi mendalam terhadap teks.
Pengajaran Utama: Reka Bentuk Tugasan Mengubah Risiko Halusinasi AI
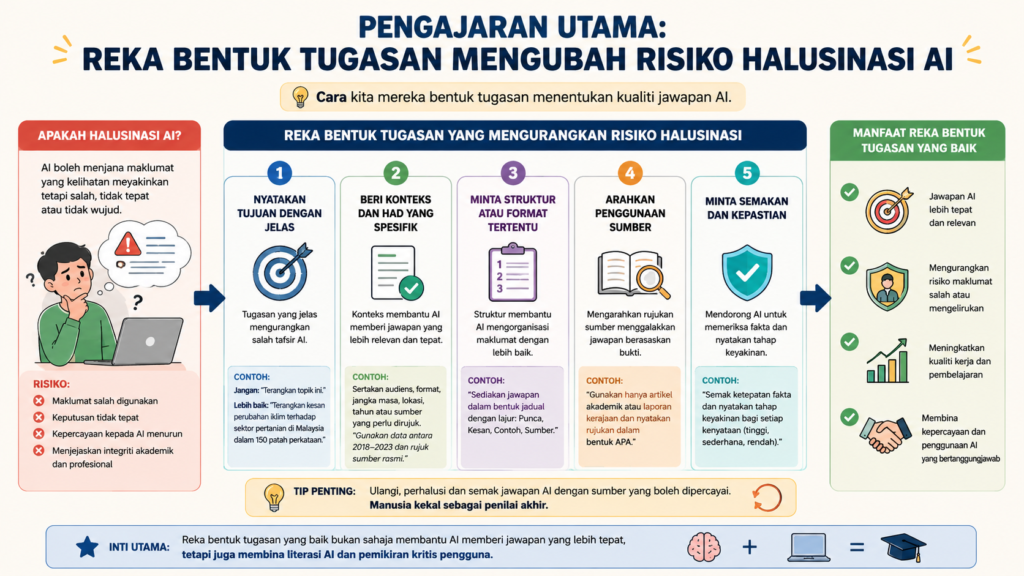
Melihat kepada data di atas, mudah untuk kita terus membuat kesimpulan tentang model mana yang terbaik. Namun, pengajaran terbesar daripada kajian Chuah et al. (2026) ini bukanlah tentang model mana yang memenangi perlumbaan, tetapi tentang Reka Bentuk Tugasan (Task Design).
“Risiko halusinasi berubah secara drastik apabila kita mengubah arahan daripada sekadar mengambil maklumat (retrieval) kepada menghubungkan idea dan membuat inferens.”
Apabila kita meminta AI memetik data sokongan yang jelas (faktual), peratusan ralat adalah rendah. Namun, sebaik sahaja tugasan memerlukan AI untuk mensintesis kandungan, menghubungkan titik-titik maklumat, dan menghasilkan interpretasi tahap tinggi, risiko halusinasi melonjak naik merentasi semua model. Sintesis data ternyata jauh lebih sukar bagi AI berbanding imbasan fakta.
Implikasi Terhadap Dunia Penyelidikan dan Pembelajaran
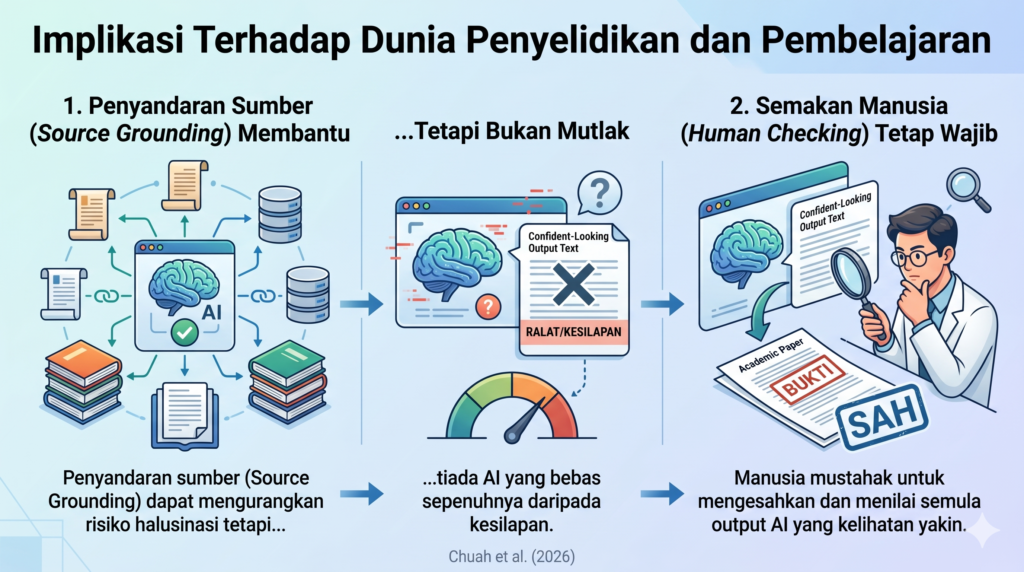
Bagi para pendidik, pelajar, dan ahli profesional, hasil kajian ini membawa dua implikasi kritikal:
- Penyandaran Sumber (Source Grounding) Membantu, Tetapi Bukan Mutlak: Menggunakan sistem yang berpaut pada sumber khusus (seperti NotebookLM) terbukti mengurangkan ralat secara signifikan. Walau bagaimanapun, kadar ralat 20% dalam interpretasi bermakna ia masih belum bebas daripada kesilapan.
- Semakan Manusia (Human Checking) Tetap Wajib: AI mempunyai sifat semula jadi untuk menjawab dengan nada yang sangat yakin, walaupun hujah atau bukti yang dikemukakannya adalah lemah atau salah. Jangan sesekali menelan bulat-bulat output AI tanpa pengesahan silang (cross-checking).
Satu Persoalan untuk Kita Fikirkan bersama…
Harus diingat, dalam kajian awal ini, para penyelidik hanya menapis dan menggunakan sumber artikel berkualiti tinggi dan sahih.
Bayangkan apa yang akan terjadi sekiranya sistem AI ini disogok dengan bahan rujukan yang diragui, berat sebelah, atau tidak mempunyai bukti saintifik yang kukuh?
Langkah Seterusnya
Kajian ini masih di peringkat awal. Pasukan penyelidik kini sedang menambah dan menganalisis lebih banyak variasi sumber serta kepelbagaian corak soalan untuk mendapatkan data yang lebih komprehensif.
Bagi anda yang kerap menggunakan AI dalam tugasan harian atau penyelidikan akademik, bagaimanakah anda menguruskan risiko halusinasi AI dalam tugasan anda? Kongsikan pengalaman anda di ruangan komen di bawah!
Nota: Ikuti blog ini untuk mendapatkan kemas kini penuh sebaik sahaja kajian rasmi ini diterbitkan secara meluas.
Sumber: https://www.facebook.com/share/1A5JXccfrs/
